
Waldo Tobler’s first law of geography is that “everything is related to everything else, but near things are more related than distant things.” This is an important idea for many aspects of spatial science, but it’s taken particularly seriously by people who draw maps and do statistics to investigate how and why disease rates vary from place to place.
If Tobler’s first law holds, we should expect the characteristics of people and places who are close together (including their health) to be similar. So, in general, the folk who live in your neighbourhood should be more like you than the folk who live on the other side of town.
This matters when we are researching if and how environment affects health. We know that people’s health can be affected by a huge range of things. If we are to reveal the health impacts that environment has, we need to try and allow for as many of those other influences as possible. However, we know that it’s very hard to account for all of them. This means some of the relationship between environment and health we see in our analyses may actually be due to these ‘unmeasured’ influences, a problem we call ‘residual confounding’. Now, if Tobler’s law is right, it is also likely that these unmeasured influences are also more similar when they are closer together. When this happens, it’s called residual spatial confounding. If we don’t allow for it, we run the risk of making mistakes in assessing the strength of relationships between the characteristics of environments and the health of the people who live there.
The good news is that these problems have long been known about and there are a range of techniques to try and deal with them. They include ways to statistically ‘smooth’ maps showing how risk of a disease varies from area to area, and to adjust measurements of risk for how close together they are in geographic space.
The bad news is that Tobler’s first law is not always true! It’s not always the case that neighbouring areas do have similar characteristics or environments. Often areas that are right next to each other contain very different types of people and have a very different environment. You have probably experienced this when walking around a town or city. You cross a road, the housing changes dramatically, and the streets ‘feel’ different. Those statistical techniques assume that kind of sudden change doesn’t happen.
Dr Duncan Lee and Prof Rich Mitchell have just finished an ESRC funded research project (RES-000-22-4256) trying to improve the way we handle this situation in our research. We have successfully created, and published techniques that can spot when two neighbourhood areas are so different that we need to alter our statistical assessment of the relationships between health and environment. One technique, published in Biostatistics, can be used when we have data that tell us something about the characteristics of the people or the neighbourhoods, such as house prices or smoking rates. The other can be used when all we have is information about health in the areas (now in press with Journal of the Royal Statistical Society Series C) .
Here’s an example of our results. The map below (click it to view full size) shows 271 areas that make up the Greater Glasgow and Clyde Health Board (for the geeks, the areas are intermediate geography zones). We obtained data on the risk of admission to hospital with a primary diagnosis of respiratory disease, from the Scottish Neighbourhood Statistics database (http://www.sns.gov.uk/). The map is shaded so the colour of each area denotes its disease risk, with a value of 1.0 representing an average risk across the whole health board. Values above 1.0 represent high risk areas (for example a value of 1.10 indicates a 10% higher risk), while values below 1.0 represent low risk areas (for example a value of 0.85 indicates a 15% reduced risk). The red lines show boundaries between neighbouring areas that contain populations at very different risk of hospital admission for respiratory disease. These are the areas in which the conventional techniques would make mistakes. There are 173 of them… that’s 25% of all the boundaries in the map.
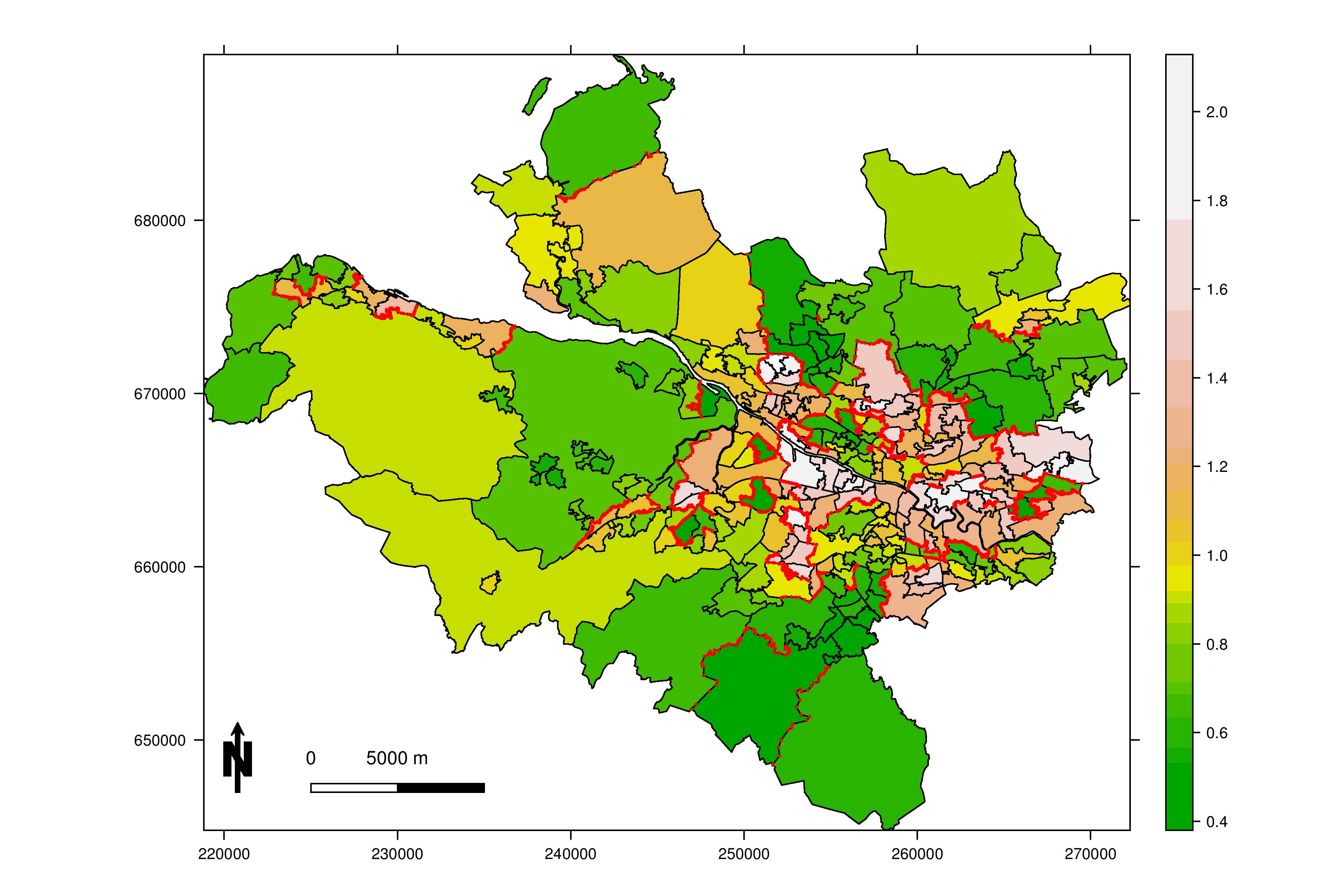
Data and boundaries © Crown Copyright. All rights reserved 2010.
We have created a free software package that will allow anyone to apply our techniques. It’s called CARBayes and is for the statistical software R. You can read about it and get it from here.
There has also been an interesting spin off from this research. Within Glasgow, we found a lot of neighbourhoods that were right next to each other but were very different in social and economic terms. We called these between-neighbourhood differences ‘social cliffs’. It prompted us to ask how such social cliffs occur. One idea is that they may be made more likely by physical barriers between the neighbourhoods, such as rivers, main roads or railways.The map below (click it to view full size) shows the kinds of physical features we’ve been looking at (note, our data are for the period before the new M74 motorway was opened).
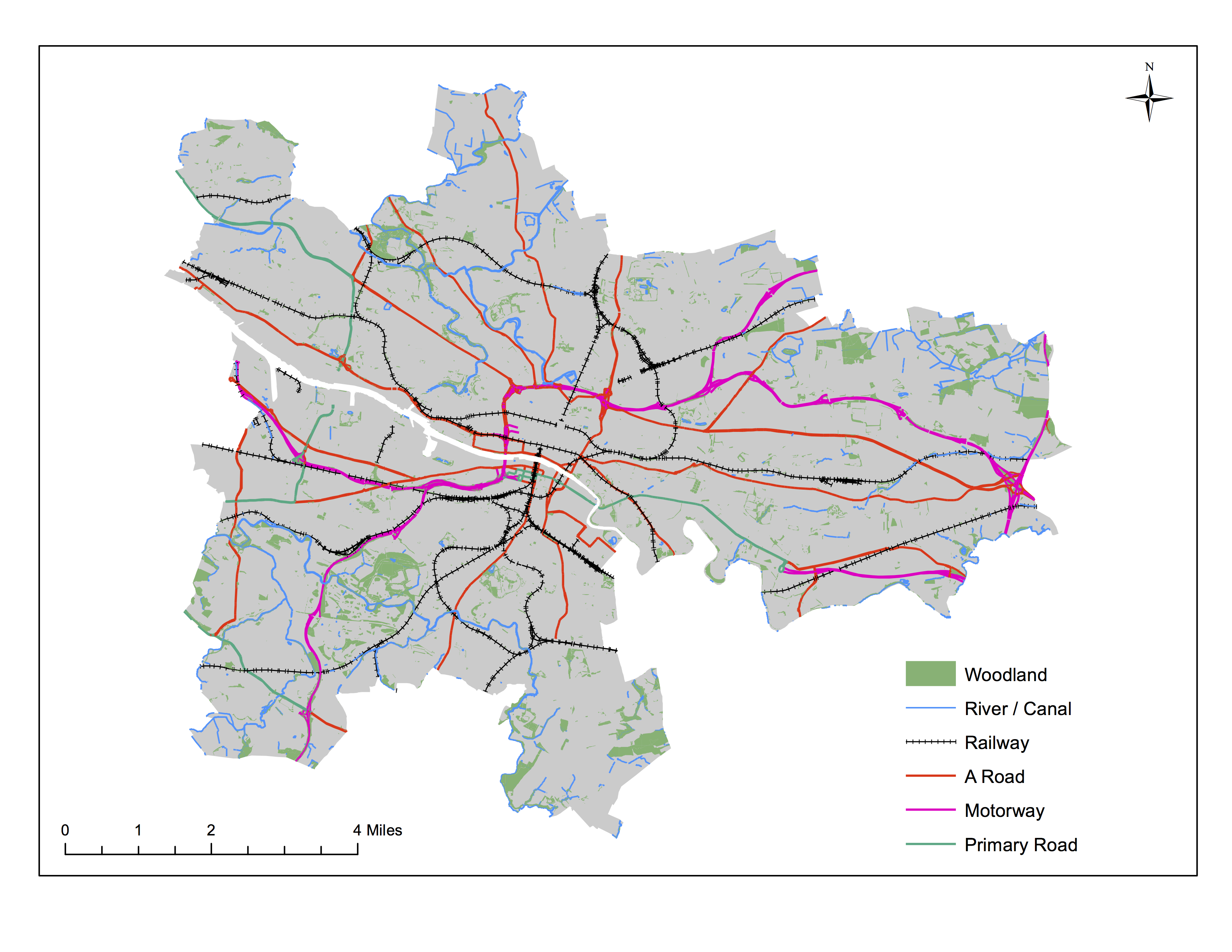
Map based on data that are © Crown Copyright/database right 2012. An Ordnance Survey/EDINA supplied service.
Our research is now complete and we’re writing it up for publication. It seems that two kinds of physical feature are especially important. Where one or both of them lie along a neighbourhood boundary, it’s much more likely that the neighbourhoods will be very different socially, and economically. Which two do you think they are?

Leave a comment